Building multi-modal Human Perception AI is an incredibly complex problem:
- Multi-modal – Human emotions and cognitive states manifest in a variety of ways including your tone of voice and your face
- Many expressions – Facial muscles generate hundreds of facial expressions of emotion, and speech has many different dimensions – from pitch and resonance to melody and voice quality
- Highly nuanced – Expressions, cognitive states, and emotions can be very nuanced and subtle, like an eye twitch or your pause patterns when speaking
- Temporal lapse – As emotions unfold over time algorithms need to measure moment-by-moment changes to accurately depict the emotional state
- Non-deterministic – Changes in facial or vocal expressions, can have different meanings depending on the person’s context at that time
- Beyond emotions – Facial and vocal analysis provides broader people analytics such as cognitive states and demographics
- Massive data – Human Perception AI algorithms need to be trained with massive amounts of real-world data that is collected and annotated
- Context – Emotion and expression metrics measured in education are different than those needed in automotive, mobile, or customer care
In addition to modeling these complexities, these Human Perception AI models need to run accurately, on-device, in real-time. Heuristic rule-based systems where humans code for all possible patterns and scenarios are not possible. Machine Learning is a must.
Human Perception AI using Deep Learning
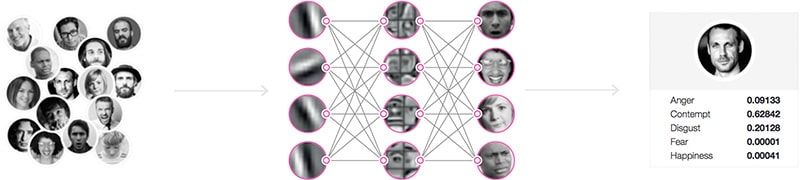
Deep learning is an exciting new area of research within machine learning which allows artificial intelligence companies like Affectiva to model more complex problems with higher accuracy than other machine learning techniques. In addition, deep learning solves a variety of problems (classification, segmentation, temporal modeling) and allows for end-to-end learning of one or more complex tasks jointly. The specific tasks address include face detection and tracking, speaker diarization, voice-activity detection, and emotion classification from face and voice.
To solve these diverse tasks, we require a suite of deep learning architectures:
- Convolutional Neural Networks (CNN)
- Multi-task (multi-attribute) networks for both regression and classification
- Region proposal networks
- Recurrent Neural Networks (RNN)
- Long Short-Term Memory (LSTM)
- Deep Recurrent Non-Negative Matrix Refactorization (DR-NMF)
- CNN + RNN nets
We don’t just use off the shelf network architectures, but focus our efforts on building custom layers and architectures designed for facialand vocal analysis tasks.
Deep Learning On-device
Deep learning models are typically very computationally expensive requiring large GPUs to compute results quickly. As a result, most deep learning models can only run as cloud based APIs, using specialized hardware.
In contrast, our deep learning models need to provide accurate, real time estimates of emotions on mobile devices. On-device performance requires exploring trade-offs between model complexity (memory, FLOPs) and model accuracy.
Our approach:
- Joint-training with shared layers between models (multi-task learning)
- Iterative benchmarking / profiling of on-device performance
- Model compression: training compact models from larger models
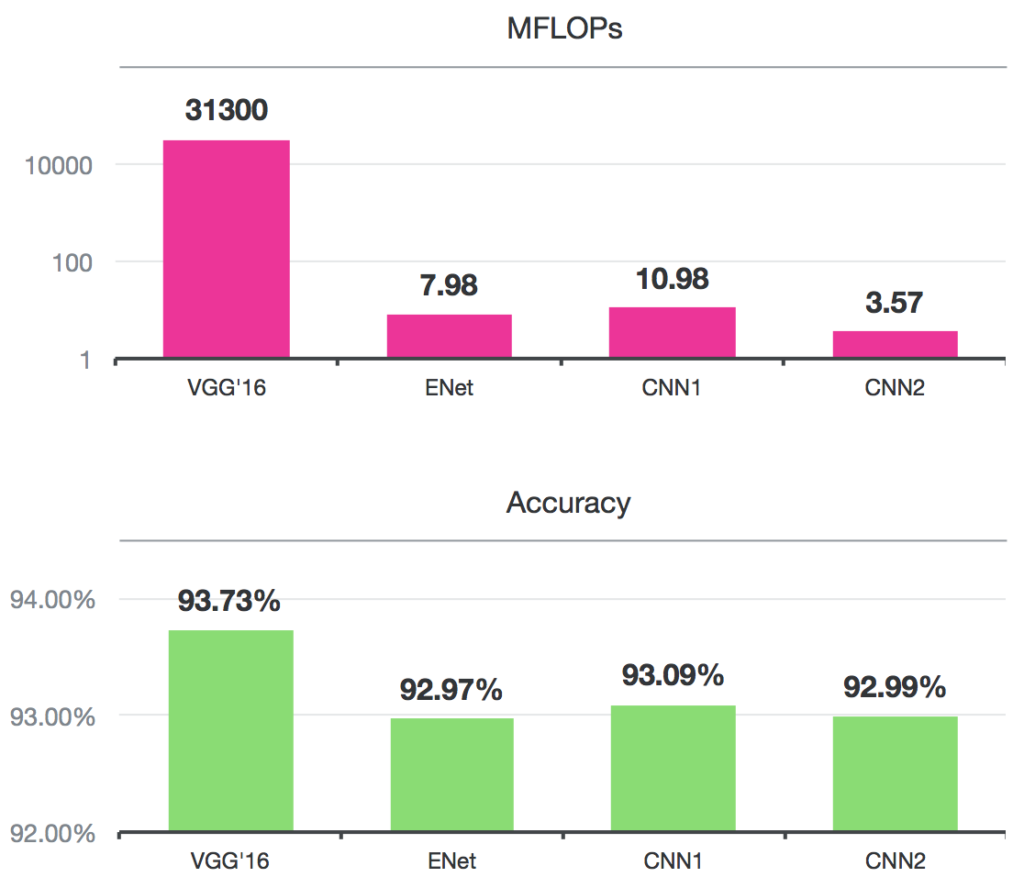 We have built models that run 10,000x faster than VGG’16 for only a less than 1% reduction in accuracy
We have built models that run 10,000x faster than VGG’16 for only a less than 1% reduction in accuracy
For more Science Resources, click here.