
Navigating the Complexity of Building Human Emotion AI
Constructing a robust human Emotion AI system poses an intricate challenge due to its inherent complexities. The intricacies arise from the multi-modal nature of human emotions and cognitive states, which are expressed through various channels such as facial expressions, tone of voice, and other gestures. These behaviors can also be interpreted using contextual information including the environment, social situation, and cultural context. Facial expressions are a rich source of information due to the vast diversity of expressions: multiple facial muscles can be used in combination to generate hundreds of emotional nuances. Other visual signals, such as head gestures and body language also play a role alongside modalities such as audio.
The subtlety of these expressions adds another layer of complexity, requiring algorithms to discern nuanced cues on the face (like the intensity or duration of smile expressions) or a combination of facial and head gestures (such as eyebrow actions or head nodding) during speech. The non-deterministic nature of facial expressions introduces an additional challenge, as the meaning can vary based on the context in which these expressions occur. Beyond mere emotional analysis, the capabilities of Human Emotion AI extend to broader people analytics, including cognitive states derived from facial signals.
Technology and Implementation
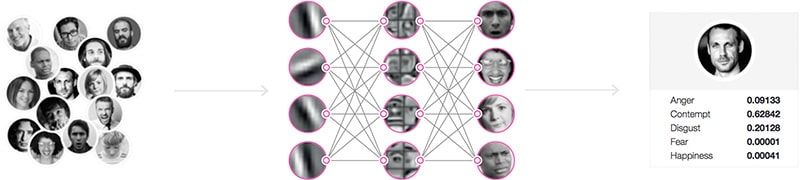
The traditional approach of heuristic (rule-based) systems, where humans code for all possible patterns and scenarios, proves impractical. Instead, the adoption of Computer Vision and Machine Learning becomes imperative for building adaptive AI models capable of comprehending the dynamic and nuanced nature of human expressions and emotions. Moreover, the context in which these algorithms operate varies across domains for example Media Analytics, behavioral research, and automotive. Differences in computational power, responsiveness, and cameras require variations of the core technology for deployment.
Our technology is device agnostic, working both on-device and via opt-in cloud-based APIs through our market research partners, optimized to work using the same cameras found on everyday devices such as mobile phones and laptops. Additionally, we offer Automotive Embedded-ready models that can efficiently process data from automotive-grade NIR cameras and systems (SoCs).
Building Trust and Transparency

Training the Emotion AI algorithms demands massive amounts of real-world data collected and meticulously annotated to ensure their efficacy. At Affectiva, we are utilizing deep learning algorithms, and we train and test our models extensively with diverse data sourced from our global dataset of over 14 million videos collected from 90 countries.
This rigorous approach ensures high accuracy and ethical AI, mitigating data and algorithmic biases and flexibly supporting our client’s needs. We believe in transparency and consent when it comes to data collection. Our standard opt-in and consent process ensures that we prioritize user privacy and ethics. Trust is paramount in the world of AI and technology, and we’re committed to building it by being straightforward with our partners and respondents on how face videos will be used for research purposes.